引言:
Java Web学习笔记
Tomcat
什么是Tomcat
Tomcat简单的说就是一个运行JAVA的网络服务器,底层是Socket的一个程序,它也是JSP和Serlvet的一个容器。
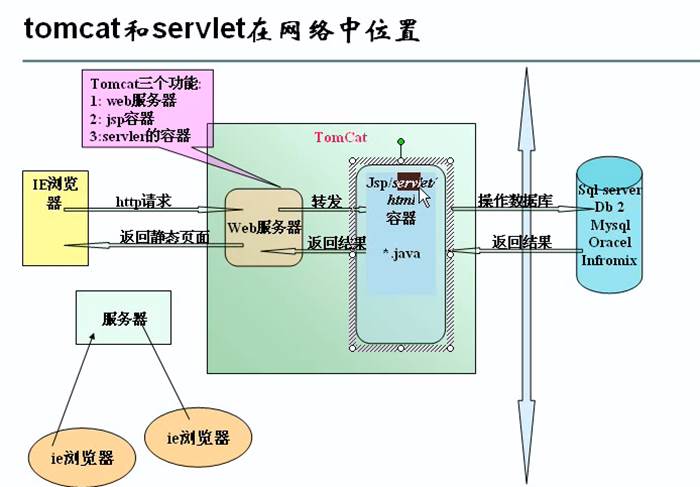
Tomcat图解
Tomcat就是提供能够让别人访问自己写的页面的一个程序
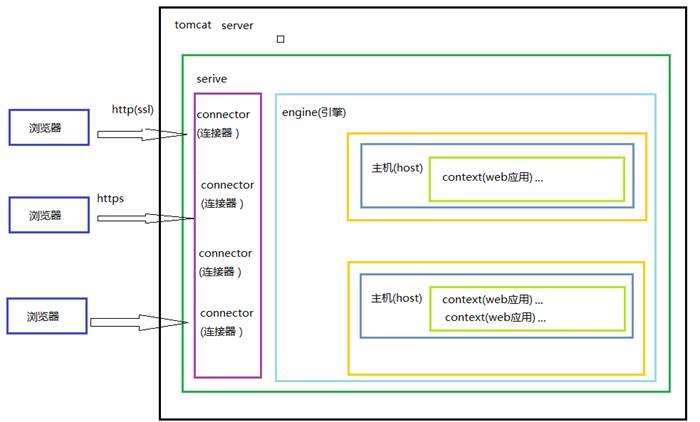
- Tomcat体系结构
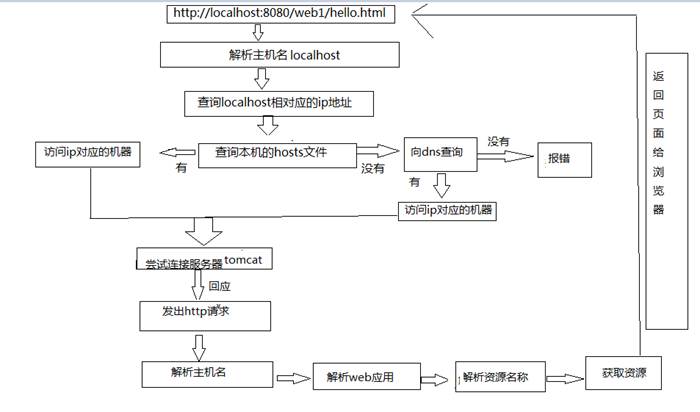
- 浏览器访问WEB资源的流程图
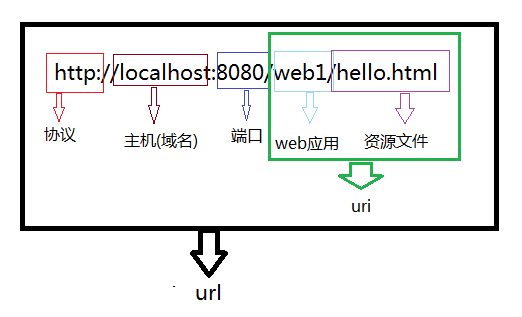
- URL图示
- Tomcat结构目录
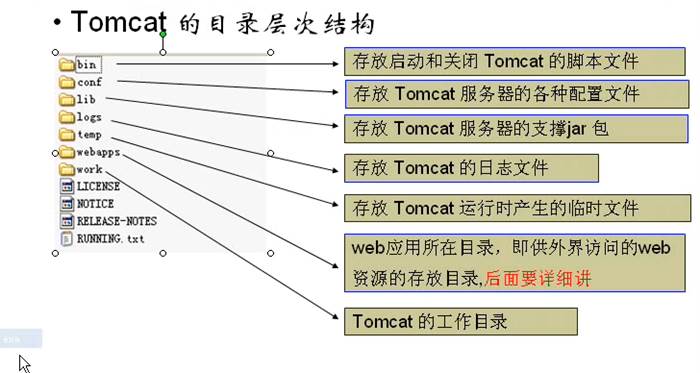
- web站点目录
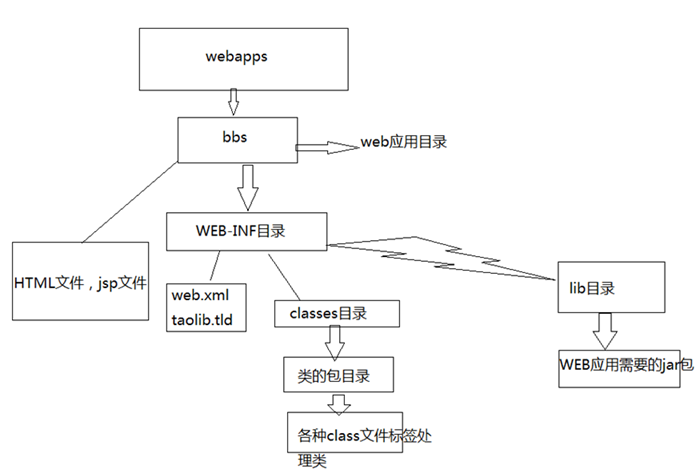
- bbs目录代表一个web应用
- bbs目录下的html,jsp文件可以直接被浏览器访问
- WEB-INF目录下的资源是不能直接被浏览器访问的
- web.xml文件是web程序的主要配置文件
- 所有的classes文件都放在classes目录下
- jar文件放在lib目录下
Servlet
概述
Servlet 是在服务器上运行的小程序。一个 servlet 就是一个 Java 类,并且可以通过 “请求—响应” 编程模式来访问的这个驻留在服务器内存里的 servlet 程序。
Java Servlet API 是 Servlet 容器 (tomcat) 和 servlet 之间的接口,它定义了 serlvet 的各种方法,还定义了 Servlet 容器传送给 Servlet 的对象类,其中最重要的就是 ServletRequest 和 ServletResponse。所以说我们在编写 servlet 时,需要实现 Servlet 接口,按照其规范进行操作。
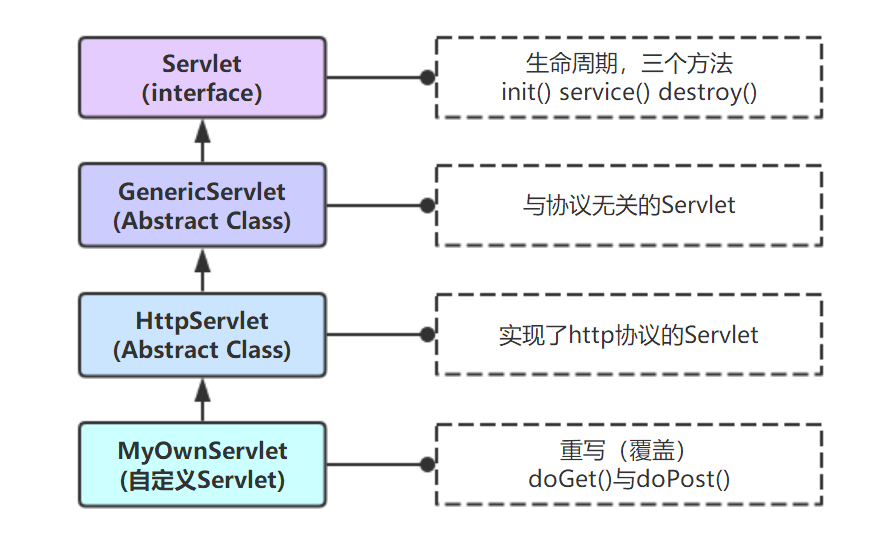
类的继承关系如下:
Tomcat & Servlet
Tomcat 是 Web 应用服务器,是一个 Servlet/JSP 容器。Tomcat 作为 Servlet 容器,负责处理客户请求,把请求传送给 Servlet,并将 Servlet 的响应传送回给客户。而 Servlet 是一种运行在支持 Java 语言的服务器上的组件。
从 http 协议中的请求和响应可以得知,浏览器发出的请求是一个请求文本,而浏览器接收到的也应该是一个响应文本。浏览器发送过来的请求也就是 request,响应回去的就用 response,如下图:
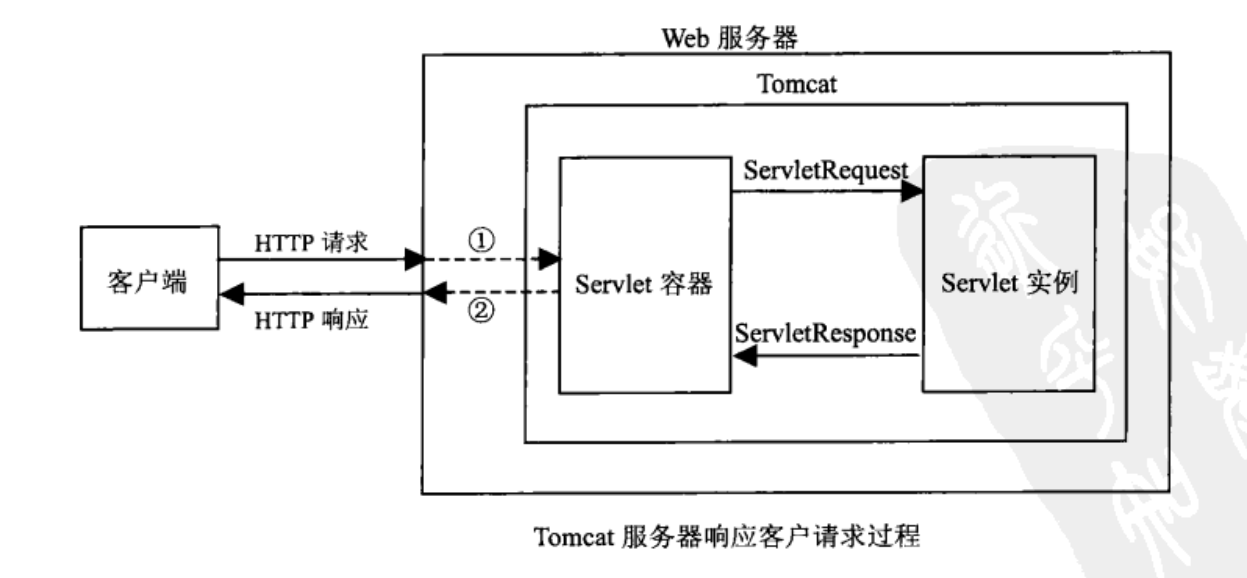
① Tomcat 将 http 请求文本接收并解析,然后封装成 HttpServletRequest 类型的 request 对象,所有的 HTTP 头数据读可以通过 request 对象调用对应的方法查询到。
② Tomcat 同时会要响应的信息封装为 HttpServletResponse 类型的 response 对象,通过设置 response 属性就可以控制要输出到浏览器的内容,然后将 response 交给 tomcat,tomcat 就会将其变成响应文本的格式发送给浏览器
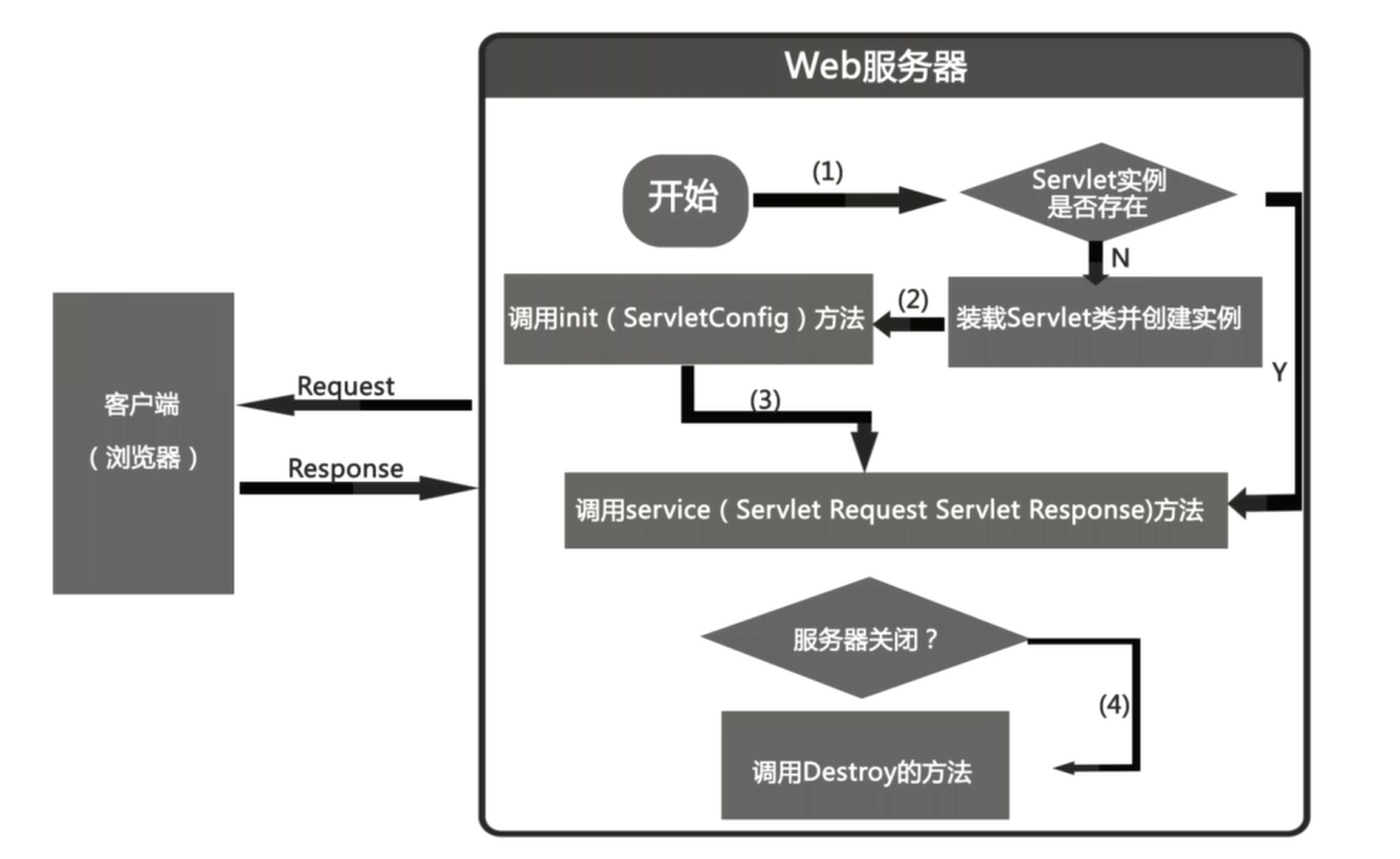
Servlet 执行流程
实现Servlet接口,需要实现5个方法。而HttpServlet类已经实现了Servlet接口的所有方法。实际编写Servlet时,只需要继承HttpServlet,重写你需要的方法即可,并且它在原有Servlet接口上添加了一些与HTTP协议处理方法,它比Servlet接口的功能更为强大。
- 一般都是重写doGet()和doPost()方法的。
主要描述了从浏览器到服务器,再从服务器到浏览器的整个执行过程
浏览器请求

浏览器向服务器请求时,服务器不会直接执行我们的类,而是到 web.xml 里寻找路径名
- ① 浏览器输入访问路径后,携带了请求行,头,体
- ② 根据访问路径找到已注册的 servlet 名称
- ③ 根据映射找到对应的 servlet 名
- ④ 根据根据 servlet 名找到我们全限定类名,既我们自己写的类
服务器创建对象
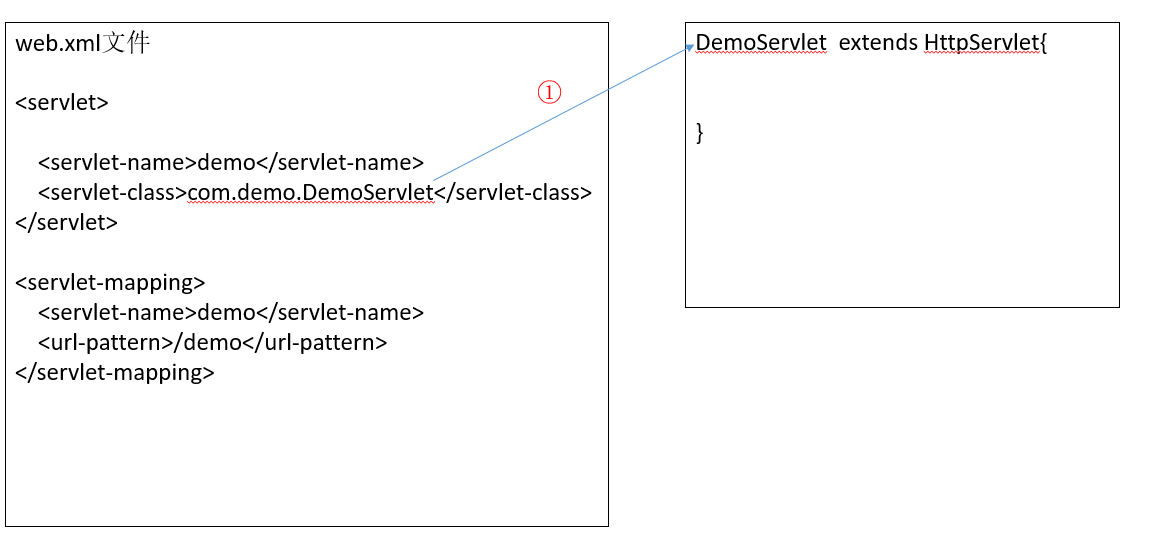
- ① 服务器找到全限定类名后,通过反射创建对象,同时也创建了 servletConfig,里面存放了一些初始化信息(注意服务器只会创建一次 servlet 对象,所以 servletConfig 也只有一个)
调用 init 方法
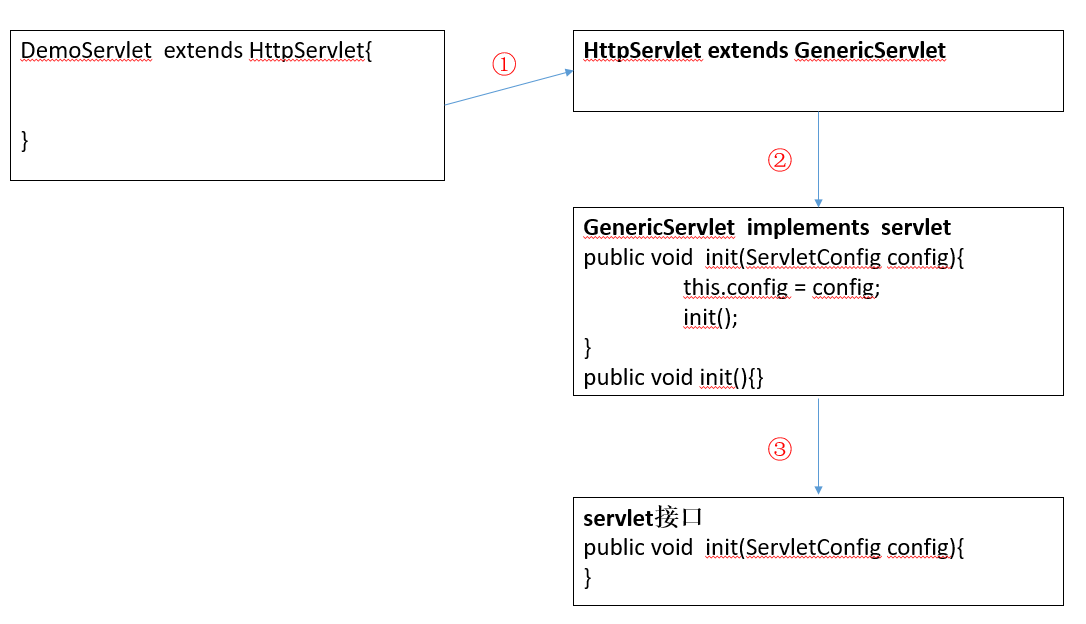
- ① 对象创建好之后,首先要执行 init 方法,但是我们发现我们自定义类下没有 init 方法,所以程序会到其父类 HttpServlet 里找
- ② 我们发现 HttpServlet 里也没有 init 方法,所以继续向上找,既向其父类 GenericServlet 中继续寻找, 在 GenericServlet 中我们发现了 init 方法,则执行 init 方法(对接口 Servlet 中的 init 方法进行了重写)
注意: 在 GenericServlet 中执行 public void init(ServletConfig config) 方法的时候,又调用了自己无参无方法体的 init() 方法,其目的是为了方便开发者,如果开发者在初始化的过程中需要实现一些功能,可以重写此方法。
调用 service 方法
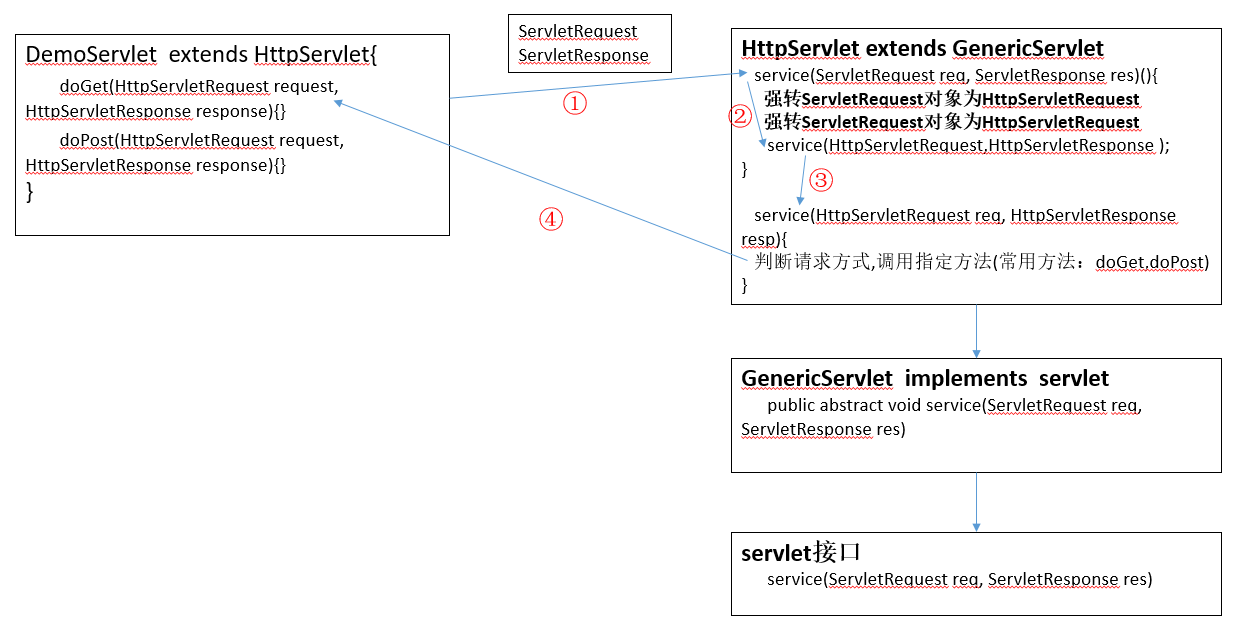
接着,服务器会先创建两个对象:ServletRequest 请求对象和 ServletResponse 响应对象,用来封装浏览器的请求数据和封装向浏览器的响应数据
① 接着服务器会默认在我们写的类里寻找 service(ServletRequest req, ServletResponse res) 方法,但是 DemoServlet 中不存在,那么会到其父类中寻找
② 到父类 HttpServlet 中发现有此方法,则直接调用此方法,并将之前创建好的两个对象传入
③ 然后将传入的两个参数强转,并调用 HttpServlet 下的另外个 service 方法
④ 接着执行 service(HttpServletRequest req, HttpServletResponse resp)方法,在此方法内部进行了判断请求方式,并执行 doGet 和 doPost,但是 doGet 和 doPost 方法已经被我们自己重写了,所以会执行我们重写的方法
为什么我们不直接重写 service 方法? 因为如果重写 service 方法的话,我们需要将强转,以及一系列的安全保护判断重新写一遍,会存在安全隐患
向浏览器响应
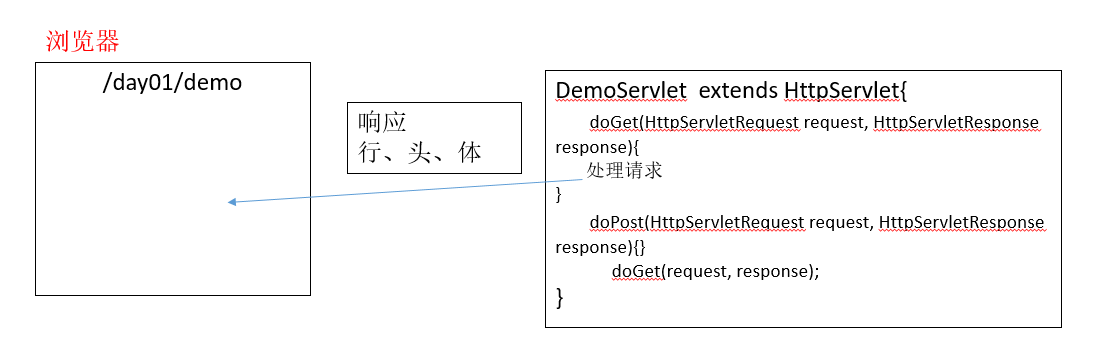
总结
- Servlet 何时创建
- 默认第一次访问servlet时创建该对象(调用
init()方法)
- 默认第一次访问servlet时创建该对象(调用
- Servlet 何时销毁
- 服务器关闭servlet就销毁了(调用
destroy()方法)
- 服务器关闭servlet就销毁了(调用
- 每次访问必须执行的方法
public void service(ServletRequest arg0, ServletResponse arg1)
- 为什么Servlet是单例的
浏览器多次对Servlet的请求,一般情况下,服务器只创建一个Servlet对象,也就是说,Servlet对象一旦创建了,就会驻留在内存中,为后续的请求做服务,直到服务器关闭。
Servlet生命周期
- 加载Servlet。当Tomcat第一次访问Servlet的时候,Tomcat会负责创建Servlet的实例
- 初始化。当Servlet被实例化后,Tomcat会调用init()方法初始化这个对象
- 处理服务。当浏览器访问Servlet的时候,Servlet会调用service()方法处理请求
- 销毁。当Tomcat关闭时或者检测到Servlet要从Tomcat删除的时候会自动调用destroy()方法,让该实例释放掉所占的资源。一个Servlet如果长时间不被使用的话,也会被Tomcat自动销毁
- 卸载。当Servlet调用完destroy()方法后,等待垃圾回收。如果有需要再次使用这个Servlet,会重新调用init()方法进行初始化操作。
Servlet细节
一个已经注册的Servlet可以被多次映射
即同一个Servlet可以映射到多个URL上。
无论访问http://localhost:8080/Demo1还是http://localhost:8080/zhang。结果都是Demo1。
1 | <servlet> |
Servlet映射的URL可以使用通配符
通配符有两种格式:
*.扩展名/*
Servlet是单例的
为什么
浏览器多次对Servlet的请求,一般情况下,服务器只创建一个Servlet对象,也就是说,Servlet对象一旦创建了,就会驻留在内存中,为后续的请求做服务,直到服务器关闭。
每次访问请求对象和响应对象都是新的
对于每次访问请求,Servlet引擎都会创建一个新的HttpServletRequest请求对象和一个新的HttpServletResponse响应对象,然后将这两个对象作为参数传递给它调用的Servlet的service()方法,service方法再根据请求方式分别调用doXXX方法。
线程安全问题
当多个用户访问Servlet的时候,服务器会为每个用户创建一个线程。当多个用户并发访问Servlet共享资源的时候就会出现线程安全问题。
原则:
如果一个变量需要多个用户共享,则应当在访问该变量的时候,加同步机制
synchronized (对象){}如果一个变量不需要共享,则直接在 doGet() 或者 doPost()定义。这样不会存在线程安全问题
load-on-startup
如果在
在web访问任何资源都是在访问Servlet
无论在web中访问什么资源【包括JSP】,都是在访问Servlet。没有手工配置缺省Servlet的时候,访问静态图片,静态网页,缺省Servlet会在你web站点中寻找该图片或网页,如果有就返回给浏览器,没有就报404错误。
ServletContext对象
ServletContext对象
当Tomcat启动的时候,就会创建一个ServletContext对象。它代表着当前web站点
ServletContext有什么用
- ServletContext既然代表着当前web站点,那么所有Servlet都共享着一个ServletContext对象,所以Servlet之间可以通过ServletContext实现通讯。
- ServletConfig获取的是配置的是单个Servlet的参数信息,ServletContext可以获取的是配置整个web站点的参数信息
- 利用ServletContext读取web站点的资源文件
- 实现Servlet的转发【用ServletContext转发不多,主要用request转发】
Servlet之间实现通讯
ServletContext对象可以被称之为域对象(可以简单理解成一个容器【类似于Map集合】)
实现Servlet之间通讯就要用到ServletContext的setAttribute(String name,Object obj)方法, 第一个参数是关键字,第二个参数是你要存储的对象。
1 | // 这是Demo2的代码 |
访问Demo3可以获取Demo2存储的信息,从而实现多个Servlet之间通讯。
获取web站点配置的信息
如果想要让所有的Servlet都能够获取到连接数据库的信息,不可能在web.xml文件中每个Servlet中都配置一下,这样代码量太大了!并且会显得非常冗余。
方法:web.xml文件支持对整个站点进行配置参数信息【所有Servlet都可以取到该参数信息】
1 | <context-param> |
1 | // Demo4代码 |
forward & redirect
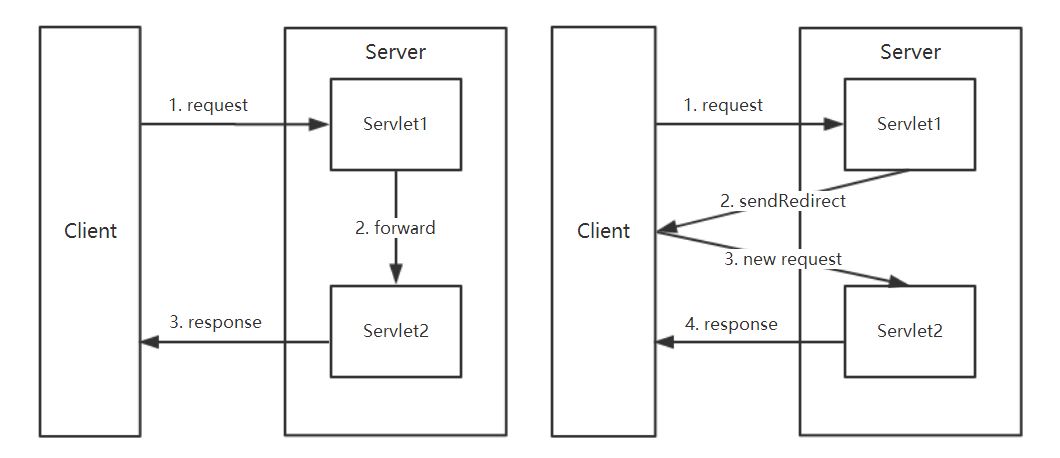
在设计 Web 应用程序时,经常需要把一个系统进行结构化设计,即按照模块进行划分,让不同的 Servlet 来实现不同的功能,例如可以让其中一个 Servlet 接收用户的请求,另外一个 Servlet 来处理用户的请求。为了实现这种程序的模块化,就需要保证在不同的 Servlet 之间可以相互跳转,而 Servlet 中主要有两种实现跳转的方式:forward 与 redirect 方式。
forward 是服务器内部的重定向,服务器直接访问目标地址的 URL,把那个 URL 的响应内容读取过来,而客户端并不知道,因此在客户端浏览器的地址栏中不会显示转向后的地址,还是原来的地址。由于在整个定向的过程中用的是同一个 Request,因此 forward 会将 Request 的信息带到被定向的 JSP 或 Servlet 中使用。
redirect 则是客户端的重定向,是完全的跳转,即客户端浏览器会获取到跳转后的地址,然后重新发送请求,因此浏览器中会显示跳转后的地址。同事,由于这种方式比 forward 方式多了一次网络请求,因此其效率要低于 forward 方式。需要注意的是,客户端的重定向可以通过设置特定的 HTTP 头或改写 JavaScript 脚本实现。
HTTP协议
什么是HTPP协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。它是TCP/IP协议的一个应用层协议
简单来说,HTTP协议就是客户端和服务器交互的一种通迅的格式。
- 例子:在浏览器点击一个链接,浏览器就为我打开这个链接的网页。
- 原理:当在浏览器中点击这个链接的时候,浏览器会向服务器发送一段文本,告诉服务器请求打开的是哪一个网页。服务器收到请求后,就返回一段文本给浏览器,浏览器会将该文本解析,然后显示出来。这段文本就是遵循HTTP协议规范的。
HTTP1.0 & HTTP1.1
- HTTP1.0协议中,客户端与web服务器建立连接后,只能获得一个web资源【短连接,获取资源后就断开连接】
- HTTP1.1协议,允许客户端与web服务器建立连接后,在一个连接上获取多个web资源【保持连接】
HTTP请求
浏览器向服务器请求某个web资源时,称之为浏览器向服务器发送了一个http请求。一个完整http请求应该包含三个部分:
请求行【描述客户端的请求方式、请求的资源名称,以及使用的HTTP协议版本号】
多个消息头【描述客户端请求哪台主机,以及客户端的一些环境信息等】
一个空行
请求行
请求行:GET /java.html HTTP/1.1
请求行中的GET称之为请求方式,请求方式有:POST,GET,HEAD,OPTIONS,DELETE,TRACE,PUT。
常用的有:POST,GET
一般来说,当我们点击超链接,通过地址栏访问都是get请求方式。通过表单提交的数据一般是post方式。
可以简单理解GET方式用来查询数据,POST方式用来提交数据,get的提交速度比post快
GET方式:在URL地址后附带的参数是有限制的,其数据容量通常不能超过1K。
POST方式:可以在请求的实体内容中向服务器发送数据,传送的数据量无限制。
请求头
Accept: text/html,image/* 【浏览器告诉服务器,它支持的数据类型】
Accept-Charset: ISO-8859-1 【浏览器告诉服务器,它支持哪种字符集】
Accept-Encoding: gzip,compress 【浏览器告诉服务器,它支持的压缩格式】
Accept-Language: en-us,zh-cn 【浏览器告诉服务器,它的语言环境】
Host: www.it315.org:80【浏览器告诉服务器,它的想访问哪台主机】
If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT【浏览器告诉服务器,缓存数据的时间】
Referer: http://www.it315.org/index.jsp【浏览器告诉服务器,客户机是从那个页面来的---反盗链】
8.User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0)【浏览器告诉服务器,浏览器的内核是什么】
Cookie【浏览器告诉服务器,带来的Cookie是什么】
Connection: close/Keep-Alive 【浏览器告诉服务器,请求完后是断开链接还是保持链接】
Date: Tue, 11 Jul 2000 18:23:51 GMT【浏览器告诉服务器,请求的时间】
HTTP响应
一个HTTP响应代表着服务器向浏览器回送数据,一个完整的HTTP响应应该包含四个部分:
- 一个状态行【用于描述服务器对请求的处理结果。】
- 多个消息头【用于描述服务器的基本信息,以及数据的描述,服务器通过这些数据的描述信息,可以通知客户端如何处理等一会儿它回送的数据】
- 一个空行
- 实体内容【服务器向客户端回送的数据】
状态行
格式: HTTP版本号 状态码 原因叙述
状态行:HTTP/1.1 200 OK
状态码用于表示服务器对请求的处理结果,它是一个三位的十进制数。响应状态码分为5类
响应头
Location: http://www.it315.org/index.jsp 【服务器告诉浏览器要跳转到哪个页面】
Server:apache tomcat【服务器告诉浏览器,服务器的型号是什么】
Content-Encoding: gzip 【服务器告诉浏览器数据压缩的格式】
Content-Length: 80 【服务器告诉浏览器回送数据的长度】
Content-Language: zh-cn 【服务器告诉浏览器,服务器的语言环境】
Content-Type: text/html; charset=GB2312 【服务器告诉浏览器,回送数据的类型】
Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT【服务器告诉浏览器该资源上次更新时间】
Refresh: 1;url=http://www.it315.org【服务器告诉浏览器要定时刷新】
Content-Disposition: attachment; filename=aaa.zip【服务器告诉浏览器以下载方式打开数据】
Transfer-Encoding: chunked 【服务器告诉浏览器数据以分块方式回送】
Set-Cookie:SS=Q0=5Lb_nQ; path=/search【服务器告诉浏览器要保存Cookie】
Expires: -1【服务器告诉浏览器不要设置缓存】
Cache-Control: no-cache 【服务器告诉浏览器不要设置缓存】
Pragma: no-cache 【服务器告诉浏览器不要设置缓存】
Connection: close/Keep-Alive 【服务器告诉浏览器连接方式】
Date: Tue, 11 Jul 2000 18:23:51 GMT【服务器告诉浏览器回送数据的时间】
HttpServletRequest
HttpServletRequest对象代表客户端的请求,当客户端通过HTTP协议访问服务器时,HTTP请求头中的所有信息都封装在这个对象中,开发人员通过这个对象的方法,可以获得客户信息。
简单来说,要得到浏览器信息,就找HttpServletRequest对象
常用方法
获得客户机【浏览器】信息
1 | getRequestURL() // 方法返回客户端发出请求时的完整URL。 |
获得客户机请求头
1 | getHeaders() 方法 |
获得客户机请求参数(客户端提交的数据)
1 | getParameter() 方法 |
Cookie
会话技术
基本概念:指用户开一个浏览器,访问一个网站,只要不关闭该浏览器,不管该用户点击多少个超链接,访问多少资源,直到用户关闭浏览器,整个这个过程我们称为一次会话。
会话常用来作为会话跟踪,例如:
- 在论坛登陆的时候,很多时候会有一个小框框问你是否要自动登陆,当你下次登陆的时候就不用输入密码了
Cookie
会话跟踪技术有 Cookie 和 Session
什么是Cookie
网页之间的交互是通过HTTP协议传输数据的,而Http协议是无状态的协议。无状态的协议是什么意思呢?一旦数据提交完后,浏览器和服务器的连接就会关闭,再次交互的时候需要重新建立新的连接。
服务器无法确认用户的信息,于是乎,W3C就提出了:给每一个用户都发一个通行证,无论谁访问的时候都需要携带通行证,这样服务器就可以从通行证上确认用户的信息。通行证就是Cookie
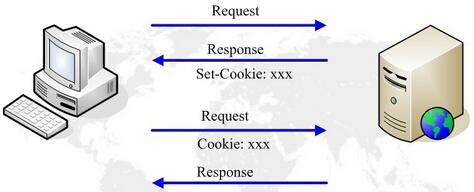
Cookie的流程:
浏览器访问服务器,如果服务器需要记录该用户的状态,就使用response向浏览器发送一个Cookie,浏览器会把Cookie保存起来。当浏览器再次访问服务器的时候,浏览器会把请求的网址连同Cookie一同交给服务器。
Cookie API
- Cookie类用于创建一个Cookie对象
- response接口中定义了一个addCookie方法,它用于在其响应头中增加一个相应的Cookie头字段
- request接口中定义了一个getCookies方法,它用于获取客户端提交的Cookie
常用的Cookie方法:
1 | public Cookie(String name,String value) |
示例:创建Cookie对象,发送Cookie给浏览器
1 | //创建Cookie对象,指定名称和值 |
浏览器本身没有任何Cookie
访问Servlet1,再回到文件夹中,已经发现文件夹中多了个Cookie的文本了
Cookie细节
Cookie不可跨域名性
Cookie具有不可跨域名性。浏览器判断一个网站是否能操作另一个网站的Cookie的依据是域名。所以一般来说,当我访问baidu的时候,浏览器只会把baidu颁发的Cookie带过去,而不会带上google的Cookie。
Cookie的有效期
Cookie的有效期是通过setMaxAge()来设置的。
如果MaxAge为正数,浏览器会把Cookie写到硬盘中,只要还在MaxAge秒之前,登陆网站时该Cookie就有效【不论关闭了浏览器还是电脑】
如果MaxAge为负数,Cookie是临时性的,仅在本浏览器内有效,关闭浏览器Cookie就失效了,Cookie不会写到硬盘中(Cookie默认值就是-1)
如果MaxAge为0,则表示删除该Cookie。Cookie机制没有提供删除Cookie对应的方法,把MaxAge设置为0等同于删除Cookie
Cookie的修改和删除
Cookie存储的方式类似于Map集合
删除方式为有限时间设置为零,修改方式为覆盖Cookie的名称相同的值。删除和修改后都要再添加到浏览器中。
1 | String name = "用户示例"; |
1 | //创建Cookie对象,指定名称和值 |
注意:删除,修改Cookie时,新建的Cookie除了value、maxAge之外的所有属性都要与原Cookie相同。如路径、编码等不一致时,浏览器将视为不同的Cookie,不予覆盖,导致删除修改失败!
Cookie的域名
Cookie的domain属性决定运行访问Cookie的域名。domain的值规定为“.域名”
- Cookie的隐私安全机制决定Cookie是不可跨域名的。
- 且同一级域名,不同二级域名也不能交接,
如果希望一级域名相同的网页Cookie之间可以相互访问。也就是说www.image.baidu.com可以获取到www.baidu.com的Cookie就需要使用到domain方法。
1 | Cookie cookie = new Cookie("name", "zhangwell"); |
使用www.image.test.com域名访问一下。发现可以获取到Cookie了
Cookie的路径
Cookie的path属性决定允许访问Cookie的路径。一般地,Cookie发布出来,整个网页的资源都可以使用。若现在只想Servlet1可以获取到Cookie,其他的资源不能获取。
1 | // 使用Servlet2颁发一个Cookie给浏览器,设置路径为"/Servlet1" |
使用Servlet3访问服务器,看看浏览器是否把Cookie带上。显然,浏览器访问Servlet3并没有把Cookie带上。
使用Servlet1访问服务器,看看浏览器是否把Cookie带上。答案是肯定的!
Cookie的应用
显示用户上次访问的时间
按照正常的逻辑来写,程序流程应该是这样子的。先创建Cookie对象,回送Cookie给浏览器。再遍历Cookie,更新Cookie的值。
但是,按照上面的逻辑是做不到的!因为每次访问Servlet的时候都会覆盖原来的Cookie,取到Cookie的值永远都是当前时间,而不是上次保存的时间。
于是换一个逻辑写:先检查(遍历)所有Cookie有没有我要的,如果得不到我想要的Cookie,Cookie的值是null,那么就认为是第一次登陆。
1 | SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); |
显示上次浏览过商品
以书籍为例!首先设计Book对象
1 | private String id ; |
使用LinkedHashMap集合【根据商品的id找书籍所以用Map,删改较多所以用Linked】作为存储数据库。
1 | private static LinkedHashMap<String, Book> linkedHashMap = new LinkedHashMap(); |
网页显示首页:
1 | printWriter.write("网页上所有的书籍:"+"<br/>"); |
添加超链接,对应书籍详情。
1 | //显示所有的书到网页上 |
书籍详情页
1 | // 接收id,找到用户想要看哪一本书,输出该书的详细信息 |
当用户点击书籍时,服务器就颁发Cookie给浏览器,记住用户点击了该书籍。这里用书籍的id作为Cookie的值,同时还要定义一些规则,定义做多显示三本书,id值使用下划线_作为分隔符。
1 | String bookHistory = null; |
取出了Cookie的值也分几种情况:
- Cookie的值为null【直接把传入进来的id当做是Cookie的值】
- Cookie的值长度有3个了【把排在最后的id去掉,把传进来的id排在最前边】
- Cookie的值已经包含有传递进来的id了【把已经包含的id先去掉,再把id排在最前面】
- Cookie的值就只有1个或2个,直接把id排在最前边
1 | if (bookHistory == null) { |
这样,Cookie值就在LinkedList集合里边了。接下来要做的就是把集合中的值取出来,拼接成一个字符串。
1 | StringBuffer stringBuffer = new StringBuffer(); |
现在已经完成了Cookie值了。接下来设置Cookie的生命周期,回送给浏览器即可
1 | String bookHistory = makeHistory(request, id); |
设置浏览记录显示
1 | printWriter.write("您曾经浏览过的商品:"); |
Session
为什么要使用Session
Session比Cookie使用方便,Session可以解决Cookie解决不了的事情【Session可以存储对象,Cookie只能存储字符串。】。
Session
什么是Session
Session 是另一种记录浏览器状态的机制。不同的是Cookie保存在浏览器中,Session保存在服务器中。用户使用浏览器访问服务器的时候,服务器把用户的信息以某种的形式记录在服务器,即Session信息。
如果说Cookie是检查用户身上的“通行证”来确认用户的身份,那么Session就是通过检查服务器上的“客户明细表”来确认用户的身份的。Session相当于在服务器中建立了一份“客户明细表”。
Session API
long getCreationTime();【获取Session被创建时间】
String getId();【获取Session的id】
long getLastAccessedTime();【返回Session最后活跃的时间】
ServletContext getServletContext();【获取ServletContext对象】
void setMaxInactiveInterval(int var1);【设置Session超时时间】
int getMaxInactiveInterval();【获取Session超时时间】
Object getAttribute(String var1);【获取Session属性】
Enumeration getAttributeNames();【获取Session所有的属性名】
void setAttribute(String var1, Object var2);【设置Session属性】
void removeAttribute(String var1);【移除Session属性】
void invalidate();【销毁该Session】
boolean isNew();【该Session是否为新的】
Session的生命周期和有效期
Session在用户第一次访问服务器Servlet,jsp等动态资源就会被自动创建,Session对象保存在内存里,这也就为什么可以直接使用request对象获取得到Session对象。如果访问HTML,IMAGE等静态资源Session不会被创建。
Session生成后,只要用户继续访问,服务器就会更新Session的最后访问时间,无论是否对Session进行读写,服务器都会认为Session活跃了一次。
由于会有越来越多的用户访问服务器,因此Session也会越来越多。为了防止内存溢出,服务器会把长时间没有活跃的Session从内存中删除,这个时间也就是Session的超时时间。
Session的超时时间默认是30分钟,有三种方式可以对Session的超时时间进行修改
Session的实现原理
服务器是如何实现一个session为一个用户浏览器服务的?
为什么服务器能够为不同的用户浏览器提供不同session?
HTTP协议是无状态的,Session不能依据HTTP连接来判断是否为同一个用户。
于是乎:服务器向用户浏览器发送了一个名为JESSIONID的Cookie,它的值是Session的id值。其实Session依据Cookie来识别是否是同一个用户。
简单来说:Session 之所以可以识别不同的用户,依靠的就是Cookie。该Cookie是服务器自动颁发给浏览器的,不用我们手工创建的。其maxAge值默认是-1,也就是说仅当前浏览器使用,不将该Cookie存在硬盘中
当我们在浏览器种访问Servlet4的时候,服务器就会创建一个Session对象,执行我们的程序代码,并自动颁发个Cookie给用户浏览器,
当我们用同一个浏览器访问Servlet5的时候,浏览器会把Cookie的值通过http协议带过去给服务器,服务器就知道用哪一Session。
而当我们使用新会话的浏览器访问Servlet5的时候,该新浏览器并没有Cookie,服务器无法辨认使用哪一个Session,所以就获取不到值。
浏览器禁用Cookie时
上面说了Session是依靠Cookie来识别用户浏览器的。如果用户浏览器禁用了Cookie了该如何处理。
Java Web提供了解决方法:URL地址重写。HttpServletResponse类提供了两个URL地址重写的方法:
1 | encodeURL(String url) |
注意:这两个方法会自动判断该浏览器是否支持Cookie,如果支持Cookie,重写后的URL地址就不会带有jsessionid了【即使浏览器支持Cookie,第一次输出URL地址的时候还是会出现jsessionid(因为没有任何Cookie可带)】
原则:把Session的属性带过去【传递给】另外一个Servlet,都要URL地址重写
URL地址重写的原理:将Session的信息重写到URL地址中。服务器解析重写后URL,获取Session的信息。这样一来,即使浏览器禁用掉了Cookie,但Session的信息通过服务器端传递,还是可以使用Session来记录用户的状态。
小结
forward和redirect的区别
实际发生位置不同,地址栏不同
- 转发是发生在服务器的
转发是由服务器进行跳转的,浏览器的地址栏是没有发生变化的。即使从servlet111 跳转到了 Servlet222 的页面,浏览器的地址还是Servlet111的。也就是说浏览器是不知道该跳转的动作,转发是对浏览器透明的。实现转发只是一次的 http 请求,一次转发中 request 和 response 对象都是同一个。这也可以解释为什么可以使用 request作为域对象进行Servlet之间的通讯。
- 重定向是发生在浏览器的
重定向是由浏览器进行跳转的,浏览器的地址会发生变化的。由浏览器进行的页面跳转实现重定向会发出两个http请求,request域对象是无效的,因为它不是同一个request对象。
用法不同
记住一个原则: 给服务器用的直接从资源名开始写,给浏览器用的要把应用名写上
1 | // 转发时"/"代表的是本应用程序的根目录【zhangwell】 |
去往的URL的范围
转发是服务器跳转只能去往当前web应用的资源
重定向是服务器跳转,可以去往任何的资源
传递数据类型不同
- 转发的request对象可以传递各种类型的数据,包括对象
- 重定向只能传递字符串
跳转的时间不同
- 转发时:执行到跳转语句时就会立刻跳转
- 重定向:整个页面执行完之后才执行跳转
如何使用
转发是带着转发前的请求的参数的。重定向是新的请求
典型的应用场景:
- 转发:访问 Servlet 处理业务逻辑,然后 forward 到 jsp 显示处理结果,浏览器里 URL 不变
- 重定向:提交表单,处理成功后 redirect 到另一个 jsp,防止表单重复提交,浏览器里 URL 变了
GET 和 POST 区别
简版对比
- Http 报文层面:GET 将请求信息放在 URL中,POST 方法报文中
- 数据库层面:GET 符合幂等性和安全性,POST 不符合
- 其他层面:GET 可以被缓存、被存储(书签),而 POST 不行
详版对比
数据携带
- GET方式:在URL地址后附带的参数是有限制的,其数据容量通常不能超过1K。
- POST方式:可以在请求的实体内容中向服务器发送数据,传送的数据量无限制。
请求参数
- GET方式:请求参数放在URL地址后面,以?的方式来进行拼接
- POST方式:请求参数放在HTTP请求包中
用途
- GET方式一般用来获取数据
- POST方式一般用来提交数据
- 原因:
- 首先是因为GET方式携带的数据量比较小,无法带过去很大的数量
- POST方式提交的参数后台更加容易解析(使用POST方式提交的中文数据,后台也更加容易解决)
- GET方式比POST方式要快
Cookie 和 Session 的区别
Cookie 简介:
- 是由服务器发给客户端的特殊信息,以文本的形式存放在客户端
- 客户端再次请求的时候,会把 Cookie 回发给服务端
- 服务器接收到后,会解析 Cookie 生成与客户端相对的内容
Cookiet 的设置以及发送过程:
Session 简介:
- 服务端的机制,在服务端保存的信息
- 解析客户端请求并操作 Session id ,按需保存状态信息
Session 的实现方式:
- 使用 Cookie 来实现
- 使用 URL 回写来实现,每次在 URL 添加 Session id 信息
简版对比
- Cookie 数据存放在客户端的浏览器上,Session 数据存放在服务器上
- Session 相对于 Cookie 更安全
- 若考虑减轻服务器负担,应当使用 Cookie
详版对比
存储方式
- Cookie只能存储字符串,如果要存储非ASCII字符串还要对其编码。
- Session可以存储任何类型的数据,可以把Session看成是一个容器
隐私安全
- Cookie存储在浏览器中,对客户端是可见的。信息容易泄露出去。如果使用Cookie,最好将Cookie加密
- Session存储在服务器上,对客户端是透明的。不存在敏感信息泄露问题。
有效期
- Cookie保存在硬盘中,只需要设置maxAge属性为比较大的正整数,即使关闭浏览器,Cookie还是存在的
- Session的保存在服务器中,设置maxInactiveInterval属性值来确定Session的有效期。并且Session依赖于名为JSESSIONID的Cookie,该Cookie默认的maxAge属性为-1。如果关闭了浏览器,该Session虽然没有从服务器中消亡,但也就失效了。
对服务器的负担
- Session是保存在服务器的,每个用户都会产生一个Session,如果是并发访问的用户非常多,是不能使用Session的,Session会消耗大量的内存。
- Cookie是保存在客户端的。不占用服务器的资源。像baidu、Sina这样的大型网站,一般都是使用Cookie来进行会话跟踪。
浏览器支持
- 如果浏览器禁用了Cookie,那么Cookie是无用的了!
- 如果浏览器禁用了Cookie,Session可以通过URL地址重写来进行会话跟踪。
跨域名
- Cookie可以设置domain属性来实现跨域名
- Session只在当前的域名内有效,不可跨域名
QA
Tomcat有几种部署方式
- 直接把Web项目放在webapps下,Tomcat会自动将其部署
- 在server.xml文件上配置
<Context>节点,设置相关的属性即可 - 通过Catalina来进行配置:进入到confCatalinalocalhost文件下,创建一个xml文件,该文件的名字就是站点的名字。编写XML的方式来进行设置。
JavaEE中的三层结构和MVC
做企业应用开发时,经常采用三层架构分层:表示层、业务层、持久层。
- 表示层负责接收用户请求、转发请求、显示数据等;
- 业务层负责组织业务逻辑;
- 持久层负责持久化业务对象。
这三个分层,每一层都有不同的模式,就是架构模式。表示层最常用的架构模式就是MVC。
因此,MVC 是三层架构中表示层最常用的架构模式。
MVC 是客户端的一种设计模式,所以他天然就不考虑数据如何存储的问题。作为客户端,只需要解决用户界面、交互和业务逻辑就好了。在 MVC 模式中,View 负责的是用户界面,Controller 负责交互,Model 负责业务逻辑。至于数据如何存储和读取,当然是由 Model 调用服务端的接口来完成。
在三层架构中,并没有客户端/服务端的概念,所以表示层、业务层的任务其实和 MVC 没什么区别,而持久层在 MVC 里面是没有的。
各层次的关系:表现层的控制->服务层->数据持久化层。
Tomcat如何创建servlet类实例?
- 当容器启动时,会读取在webapps目录下所有的web应用中的web.xml文件,然后对 xml文件进行解析,并读取servlet注册信息。然后,将每个应用中注册的servlet类都进行加载,并通过反射的方式实例化。
- 在servlet注册时加上
1 如果为正数,则在一开始就实例化,如果不写或为负数,则第一次请求实例化。