引言
他山之石记录
ArrayList元素删除
对JAVA集合进行遍历删除时务必要用迭代器
正确方式:
1 | public class MyTest { |
原因:源码分析
1 | public E remove(int index) { |
ArrayList的删除方法,将指定位置元素删除,然后将当前位置后面的元素向前拷贝的方式移动。但是注意一点细节,modCount++这步操作,将ArrayList的修改次数加1。而后面遍历时发现是通过使用这个字段来判断,当前的集合类是否被并发修改。
使用Itr提供的remove方法,可以发现modCount的变化,所以是不需要考虑modCount修改次数不一致的问题。
一段在ArrayList循环中删除元素并返回的代码:
1 | public List<A> getUserDebitCard(A cond) { |
数组转换为ArrayList
最普遍也是被最多人接受的答案如下:
ArrayList<Element> arrayList = new ArrayList<Element>(Arrays.asList(array));
缓存模式及缓存数据一致性
Cache-Aside
最常见的一种模式,是一种控制逻辑都实现在应用程序中的模式。缓存不和数据库直接进行交互,而是由应用程序来同时和缓存以及数据库打交道。
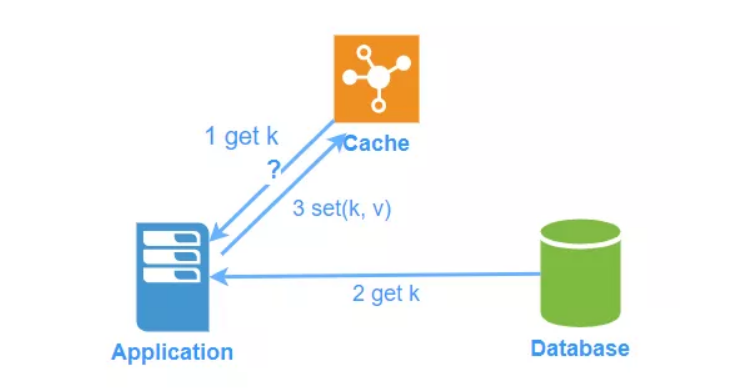
读数据时:
- 程序需要判断缓存中是否已经存在数据。
- 当缓存中已经存在数据(也就是缓存命中,cache hit),则直接从缓存中返回数据
- 当缓存中不存在数据(也就是缓存未命中,cache miss),则先从数据库里读取数据,并且存入缓存,然后返回数据
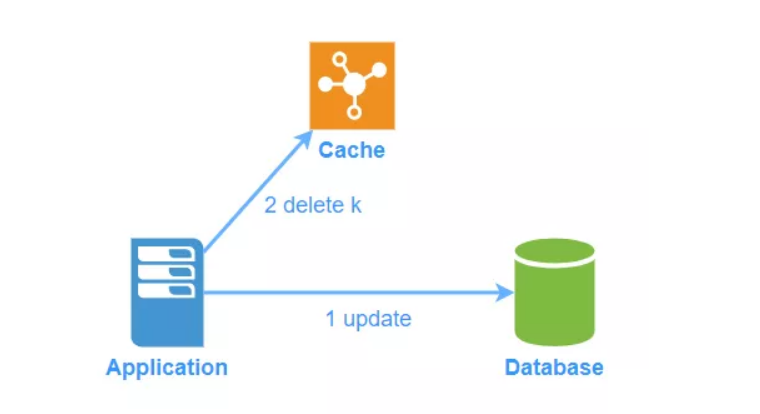
写数据时:
- 更新数据库
- 删除缓存中对应的数据
有线程安全的问题吗?有,试想一下有两个线程,线程A读,线程B写
- A读数据,由于未命中那么从数据库中取数据
- B写数据库
- B删除缓存
- A由于网络延迟比较慢,将脏数据写入缓存
但是这种情况可能性非常的小,需要同时满足很多条件,近乎不太可能发生,所以我们一般都采用这种写策略。另外可以对缓存中的数据设置合适的过期时间,即使发生的脏数据的情况,也不会发生很长时间。
应用场景:
应用于缓存不支持Read-Through/Write-Through的系统。
优点:
- 缓存仅仅保存被请求的数据,属于懒加载模式(Lazy Loading),和下文的Write-Through模式相比,避免了任何数据都被写入缓存造成缓存频繁的更新。
缺点:
- 当发生缓存未命中的情况时,则会比较慢,因为要经过三个步骤:查询缓存,从数据库读取,写入缓存。
- 复杂的逻辑都在应用程序中,如果实现微服务,多个微服务中会有重复的逻辑代码
Read-Through/Write-Through
这种模式中,应用程序将缓存作为主要的数据源,而数据库对于应用程序是透明的,更新数据库和从数据库的读取的任务都交给缓存来代理了,所以对于应用程序来说,简单很多。
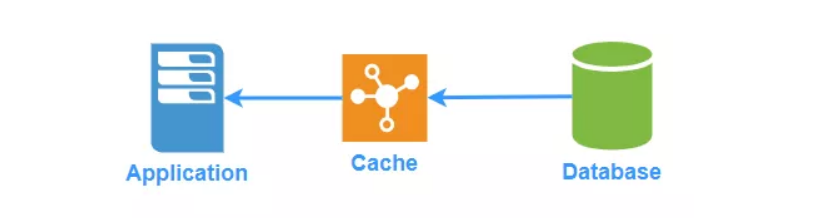
Read-Through
由缓存配置一个读模块,它知道如何将数据库中的数据写入缓存。在数据被请求的时候,如果未命中,则将数据从数据库载入缓存。
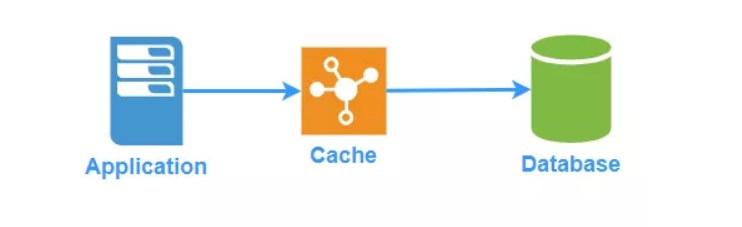
Write-Through
缓存配置一个写模块,它知道如何将数据写入数据库。当应用要写入数据时,缓存会先存储数据,并调用写模块将数据写入数据库。
应用场景:
Read Through/Write Through适用于写入之后经常被读取的应用。
优点:
- 缓存不存在脏数据
- 相比较Cache-Aside懒加载模式,读取速度更高,因为较少因为缓存未命中而从数据库中查找
- 应用程序的逻辑相对简单
缺点:
- 对于总是写入却很少被读取的应用,那么Write-Through会非常浪费性能,因为数据可能更改了很多次,却没有被读取,白白的每次都写入缓存造成写入延迟。
除了Write-Through以外,我们还有另外的两种写模式可以和Read-Through一起来配合使用,分别是Write-Back和Write-Around。
Write-Back
又叫做Write-Behind。和Write-Through写入的时机不同,Write-Back将缓存作为可靠的数据源,每次都只写入缓存,而写入数据库则采用异步的方式,比如当数据要被移除出缓存的时候再存储到数据库或者一段时间之后批量更新数据库。
应用场景
读写效率都非常好,写的时候因为异步存储到数据库,提升了写的效率,适用于读写密集的应用。
优点
- 写入和读取数据都非常的快,因为都是从缓存中直接读取和写入。
- 对于数据库不可用的情况有一定的容忍度,即使数据库暂时不可用,系统也整体可用,当数据库之后恢复的时候,再将数据写入数据库。
缺点
- 有数据丢失的风险,如果缓存挂掉而数据没有及时写到数据库中,那么缓存中的有些数据将永久的丢失了
Write-Around
和Write-Through不同,更新的时候只写入数据库,不写入缓存,结合Read-Through或者Cache-Aside使用,只在缓存未命中的情况下写缓存。
应用场景
适合于只写入一次而很少被读取的应用。
优点
- 相比较Write-Through写入的时候的效率较高,如果数据写入后很少被读取,缓存也不会被没用到的数据占满。
缺点
- 如果数据会写入多次,那么可能存在缓存和数据库不一致